While the recent advances in Multimodal Large Language Models (MLLMs) constitute a significant leap forward in the field, these models are predominantly confined to the realm of input-side multimodal comprehension, lacking the capacity for multimodal content generation. To fill this gap, we present GPT4Video, a unified multi-model framework that empowers Large Language Models (LLMs) with the capability of both video understanding and generation. Specifically, we develop an instruction-following-based approach integrated with the stable diffusion generative model, which has demonstrated to effectively and securely handle video generation scenarios. GPT4Video offers the following benefits: 1) It exhibits impressive capabilities in both video understanding and generation scenarios. For example, GPT4Video outperforms Valley by 11.8% on the Video Question Answering task, and surpasses NExt-GPT by 2.3% on the Text to Video generation task. 2) it endows the LLM/MLLM with video generation capabilities without requiring additional training parameters and can flexibly interface with a wide range of models to perform video generation. 3) it maintains a safe and healthy conversation not only in output-side but also the input side in an end-to-end manner. Qualitative and qualitative experiments demonstrate that GPT4Video holds the potential to function as a effective, safe and Humanoid-like video assistant that can handle both video understanding and generation scenarios.
Video Encoding stage: The video encoding module employs a frozen ViT-L/14 model to capture raw video features, while the video abstraction module utilizes a transformer-based cross attention layer and two novel learnable tokens, designed to condense information along the temporal and spatial axes.
LLM reasoning: The core of GPT4Video is powered by a frozen LLaMA model, efficiently fine-tuned via LoRA. The LLM is trained with custom video-centric and safety-aligned data, enabling it to comprehend videos and generate appropriate video prompts (indicated by underlined text).
Video Generation The prompts generated by LLM are then used as text inputs for the models in the Text-to-Video Model Gallery to create videos. We use ZeroScope as our video generation model in this work.
We meticulously crafted an instruction-following dataset to train the LLM to generate suitable prompts for text-to-video models at appropriate times.
We used the string "<video> Video Caption </video>" as a placeholder for the actual video in the prompt to GPT-4 and require GPT-4 to construct three dialogues between two individuals (not a person and an assistant like most other LLMs) centered around the provided Video Caption. Here is an example:
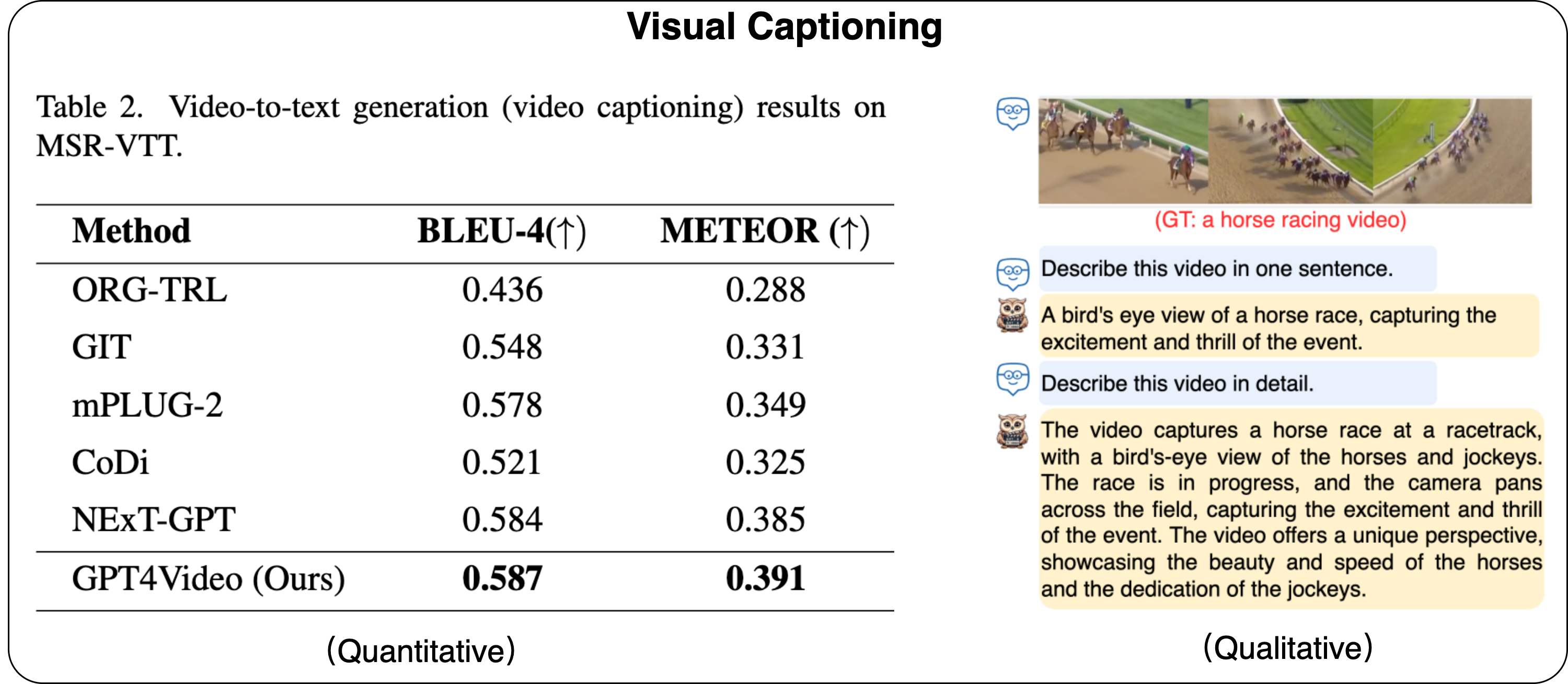
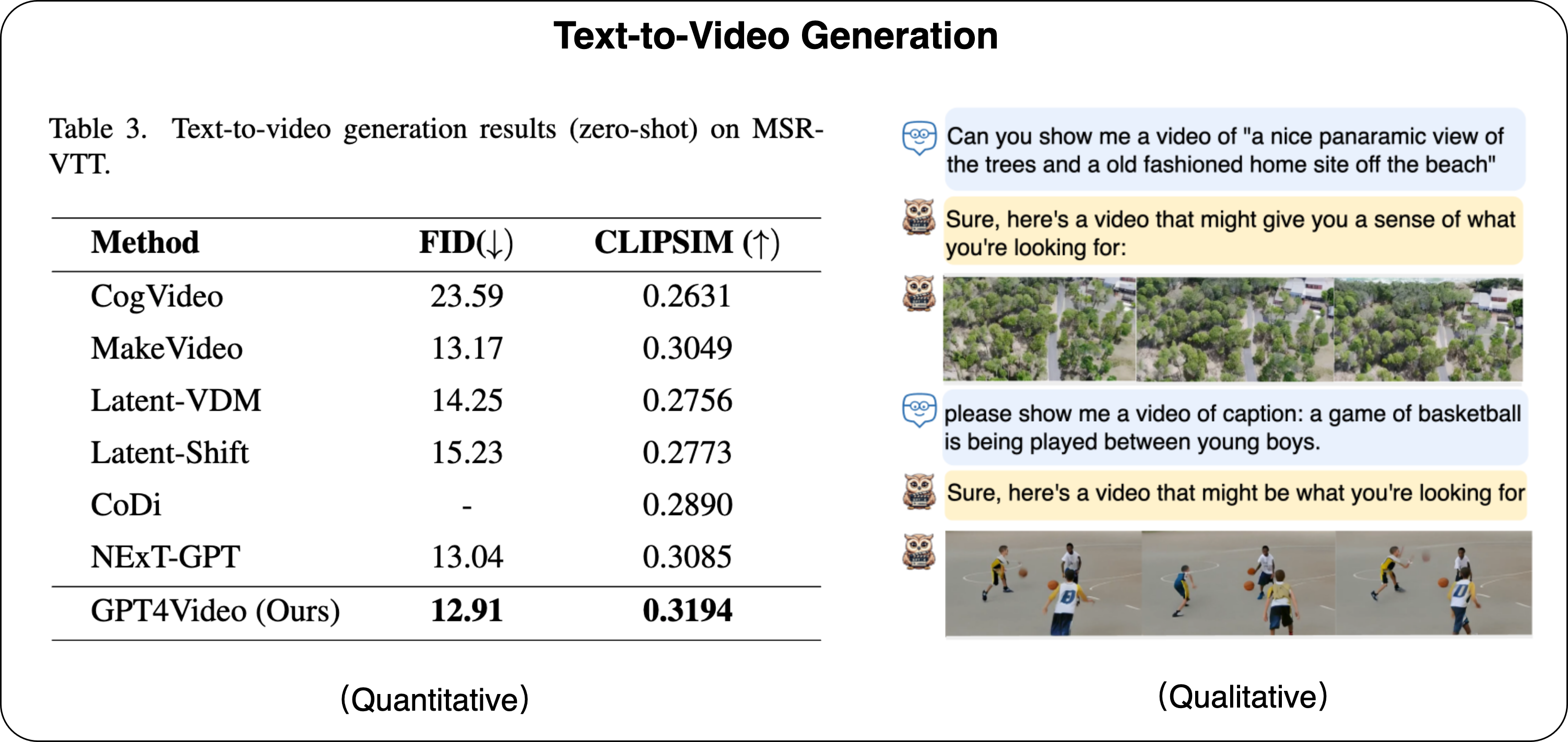
<videoX> Video Caption </videoX>" to denote the actual videos, where "X" represents the video index, "Video Caption" is the description of the content of video X. We employed a text retrieval-based approach to ensure semantic similarity between VideoX, and then requested GPT-4 to construct dialogues around those videoX. 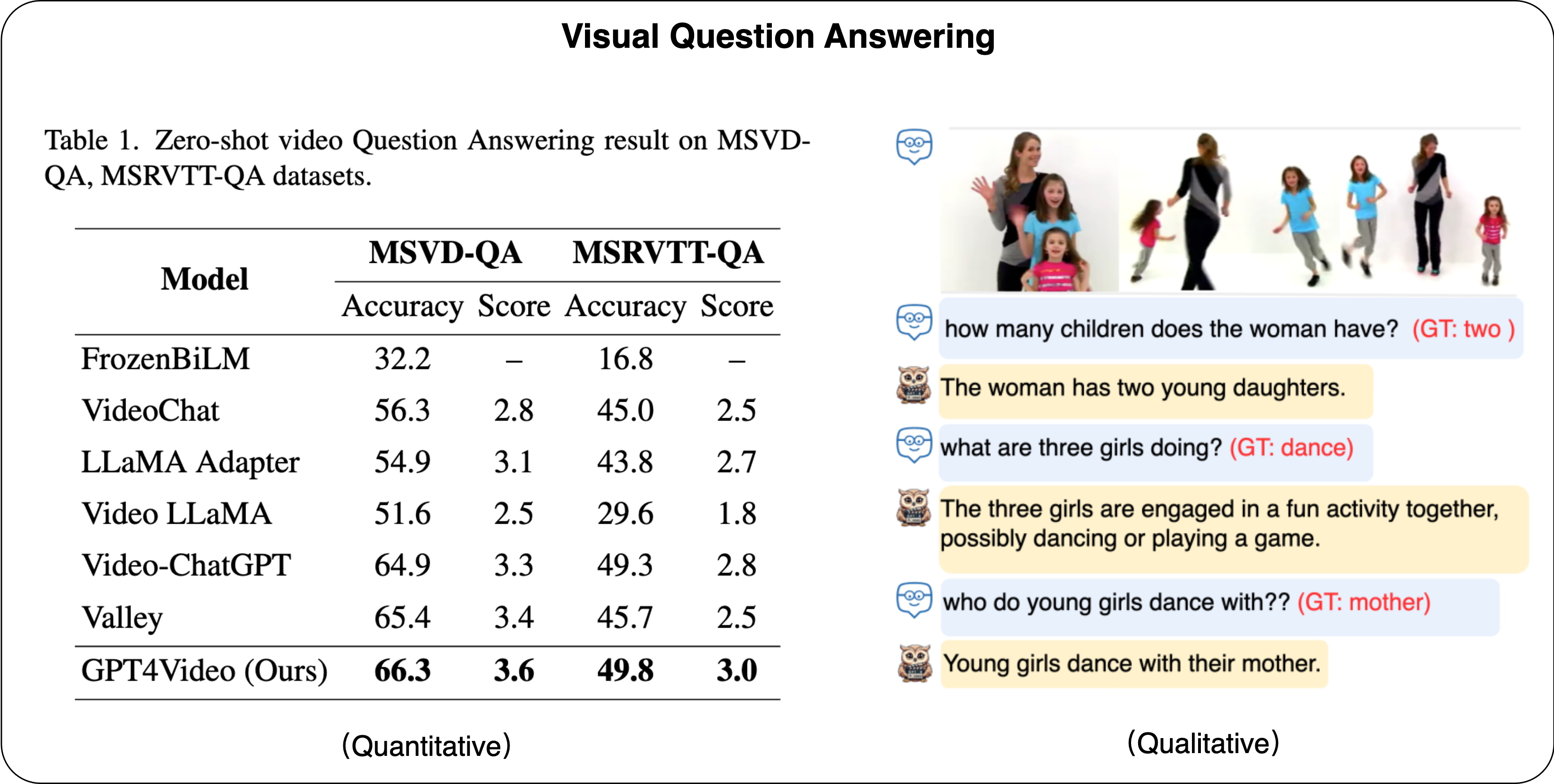
@articles{wang2023gpt4video,
title={GPT4Video: A Unified Multimodal Large Language Model for lnstruction-Followed Understanding and Safety-Aware Generation},
author={Zhanyu Wang, Longyue Wang, Minghao Wu, Zhen Zhao, Chenyang Lyu, Huayang Li, Deng Cai, Luping Zhou, Shuming Shi, Zhaopeng Tu},
journal = {CoRR},
year={2023}
}